Hur vi valde ML-modellen som driver din prognos. En titt bakom kulisserna på 15+ modeller, 4 000 verifierade kantarellobservationer från County Mayo och rättvis examination 2025.
Toppen av kantarellsäsongen i Irland inföll i september 2021. År 2025 låg toppen i juli. Två månader skillnad, samma art, samma land. Kalendern stämmer inte alltid, vädret varierar från år till år, och fjolårets dagbok upprepas inte alltid. I County Mayo har vårt team samlat över 4 000 verifierade kantarellobservationer på sex år, och 2025 tog vi det dataset och lät 15 olika ML-modeller genomgå en rättvis examination. Den här artikeln handlar om hur vi jämförde dem, vem som vann och varför du nu använder just denna modell i ShroomCast.

Varför prognostisera svamp överhuvudtaget
Skogen är ingen kalender. Titta på kantarellobservationer i hela Irland under de senaste 7 säsongerna i ett enda diagram:
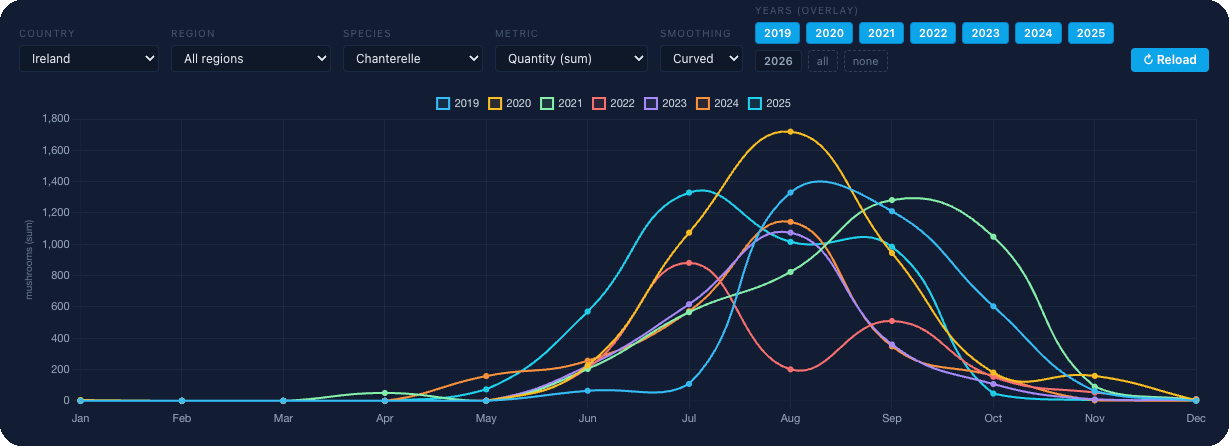
År 2021 hade du kört till skogen i juli och hittat bara mossa. År 2025 hade du väntat till september och missat toppen med sex veckor. Detta är ingen engångsavvikelse, det är normen: temperatur, nederbörd, markfuktighet, skogstyp, månfaser, var och en av dessa förskjuter fruktbildning med dagar och veckor, och deras kombinerade effekt kan dra säsongstoppen från juli till september och tillbaka.
Så har svampplockare arbetat ”på magkänsla” i århundraden, på dåligt formaliserade tecken som ”efter åskvädret, om fyra dagar, gå till ekdungen.” I vissa skogar och säsonger fungerar det. På land- och årsnivå är det ett lotteri.
Med data blir problemet lösbart. Om du har tusentals faktiskt registrerade fruktbildningar för en region kopplade till vädret dessa dagar, kan du hitta mönster i datat och förutsäga nästa utbrott. Det är problemet ShroomCast existerar för att lösa.
Data. Grunden
Vid dagens release:
- 750K+ verifierade svampobservationer sedan 2019.
- 230+ regioner som täcks av modellen i Europa.
- 7+ år av väderdata för var och en av dessa regioner.
- 14 arter modelleras individuellt (kantarell, stensopp, murkla, rödgul trumpetsvamp, brun stensopp, honungsskivling med flera).
Vi samlar källor på samma sätt varje gång: offentliga observationsdatabaser plus vårt teams egna fältanteckningar och betrodda källor vi samarbetar direkt med. Varje post är inte bara ”hittade det den dagen” utan en tripel (region, art, datum) plus full väder- och markkontext kring den dagen.
Vad vi analyserar
Varje art i varje region modelleras separat. Kantarell har sina triggers, murkla har sina, stensopp har sina. Inom en modell tittar vi på fem grupper av egenskaper:
- Väder: lufttemperatur, nederbörd, luftfuktighet, lufttryck, molntäcke.
- Mark: marktemperatur, markfukt, sammansättning.
- Skog: typ (barr, löv, blandad), höjd över havet, lokalt mikroklimat.
- Naturcykler: månfaser, säsongsmönster, artspecifika fruktbildningsfönster.
- Historisk dynamik: vad som hände i denna region med denna art under tidigare år vid liknande förhållanden.
Fallstudie: County Mayo, Irland, kantarell
För att visa hur vi väljer modell tar vi en region och en art. Mayo är den ideala testbädden av flera skäl: en stor pool av observationer över många år (mer än 4 000 enbart för kantarell), plus att vi kompletterade datasetet med kantarelldata för hela Irland för kontext.
Från 2019 till 2024 var vår träningsperiod. Modellerna ”lärde sig” på dessa sex säsonger: vilka kombinationer av väder och mark som föregick faktiska fruktbildningar, vilka som inte gjorde det. Vi lämnade 2025 orört. Det är framtiden ingen modell hade sett under träningen.
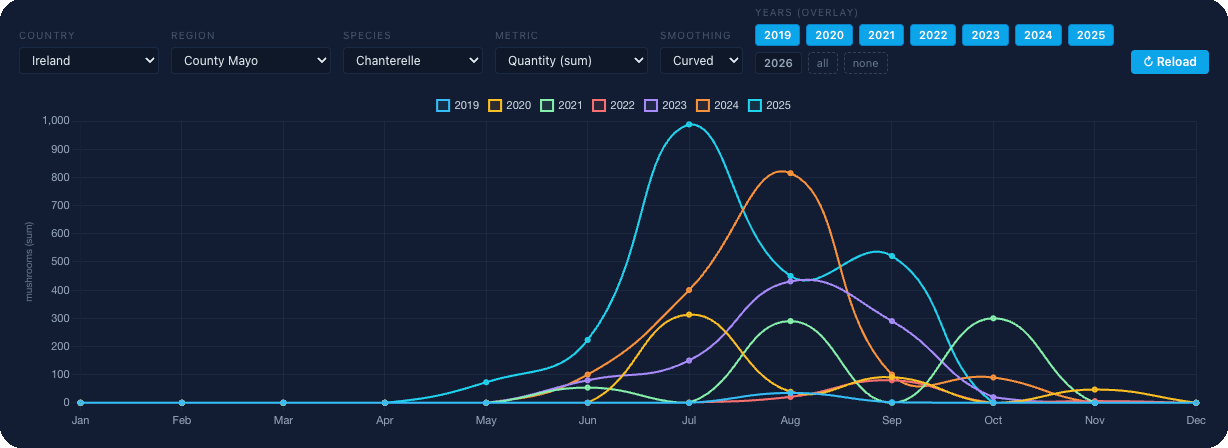
Varje punkt i diagrammet ovan är antingen ett fynd av vårt team eller en verifierad observation från betrodda källor vi arbetar med. Inga härledda data. Endast vad en människa faktiskt såg och registrerade.
Hur vi valde modellen
Det är den del de flesta användare aldrig ser: modellanbudet.
Vi körde mer än 15 olika ML-arkitekturer. Deras specifika namn spelar mindre roll än själva tillvägagångssättet: varje modell tittade på samma data och fick lära sig att förutsäga sannolikheten för kantarellfruktbildning i Mayo varje vecka 2025. Inom varje arkitektur provade vi dussintals variationer: olika egenskapshorisonter, olika regulariseringsstrategier, olika sätt att koda säsongsvariation.
Huvudregeln för urval: en modell bedömdes inte på hur väl den kom ihåg de gamla datan (vilken överanpassad maskin som helst kan göra det) utan på hur exakt den förutsäger 2025, året den inte hade sett under träningen. Det är den rättvisa examinationen.
Modell 1 mot Modell 2
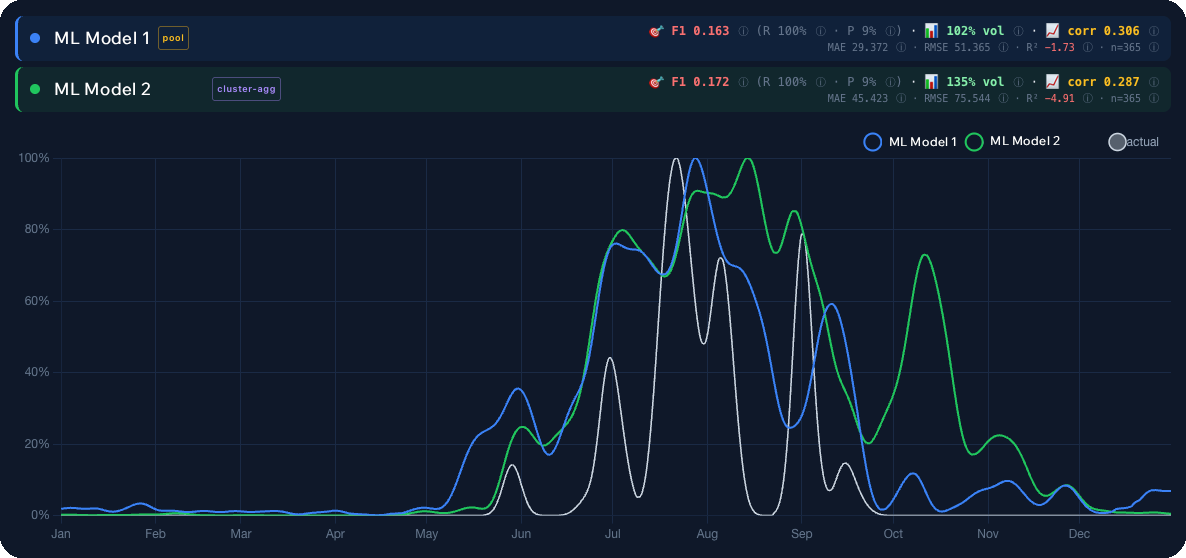
Diagrammet ovan visar samma uppsättning verkliga 2025-observationer med prognoser från två finalistmodeller överlagrade. Den blå linjen (ML Modell 1) följer de verkliga utbrotten rent: den fångar säsongstart, missar inte augustitoppen och avtar korrekt genom oktober. Den andra varianten antingen släpar efter eller överskattar intensiteten under ”tysta” veckor.
Skillnaden ser liten ut för ögat men är enorm i praktiken. En extra ”Utmärkt” prognos under en svampfri vecka kostar dig en bortkastad dag och en tank bränsle. En missad topp kostar dig säsongen. Så vinnaren blev modellen som i genomsnitt vilseledde användaren minst under 2025.
Vi körde samma procedur för varje art och för var och en av de 230+ regionerna. Samma arkitektur vann inte överallt. I regioner med en tunnare observationsbas vann mer konservativa modeller, i täta regioner tog mer känsliga varianter ledningen. Den slutliga produktionspipelinen är monterad från dessa lokalt optimala val.
Vad som faktiskt levereras i appen
De vinnande modellerna körs i produktion och beräknar nu en 14-dagars prognos för varje art i din region. Fyra gånger om dygnet hämtar pipelinen färskt väder, uppdaterar egenskaper, kör modellen och publicerar resultatet. Du ser det som den färgkodade skalan:
- 0-20% Mycket låg (lila, inte idag)
- 20-40% Låg (blå, nästan ingen chans)
- 40-60% Måttlig (grön, värt att kolla dina vanliga ställen)
- 60-80% Hög (gul, förhållandena är goda)
- 80-100% Utmärkt (orange, ta korgen)
Så allt som kommit ut av tusentals timmar modellträning är fem färger och ett nummer per dag. Så ska det vara. Komplex modell, enkelt svar.
Var det fungerar bäst och var det inte gör det
Transparens är en del av produkten. Inte alla regioner har lika tät data, och vi döljer det inte.
Starkast: Storbritannien och Irland. Här har vi den högsta observationsdensiteten och de längsta artspecifika serierna. Mayo ovan är en bild av hur en välmättad region ser ut.
Solid: södra halvan av Sverige (Götaland och större delen av Svealand). Vi utökade täckningen här nyligen och får redan en stadig signal.
Svagare: norra Sverige (Norrland), särskilt subarktiska Norrbotten. Fruktbildningsfönstren är kortare, observationerna färre. Modellen körs fortfarande men osäkerhetsbandet är bredare. Vi visar detta ärligt i appen: där datan är tunn är prognosen mer försiktig.
Detta är inte ett fel, det är så problemet är format. Mer data, skarpare svar. Varje säsong lägger vi till nya observationer och omkalibrerar modellerna.
Varför en region, inte en pin
En teknisk punkt som dyker upp regelbundet. ShroomCast visar medvetet inte prognoser på specifika punkter på kartan. Endast per region (tiotals kvadratkilometer).
Skälet är inte tekniskt. Om appen sa ”i den gläntan, 50 meter norr om denna sväng, är det 92% sannolikhet för kantarell idag”, skulle den gläntan inte längre finnas en vecka senare. Skogar överlever inte koordinatledda räder. Så vi arbetar på regional nivå och lämnar personliga ställen till svampplockarna själva.
ShroomCast lagrar inte dina platser. Kommer inte ihåg var du gick. Bygger inte din personliga karta. Detta är avsiktligt, inte en försummelse.
Vad som kommer härnäst
Just nu täcker vi Storbritannien, Irland och Sverige. Nästa release är Frankrike, sedan kontinentala Europa bredare. Vi lägger till nya arter när observationsbasen växer tillräckligt för att stödja dem (minst ett par tusen validerade observationer per region, annars är modellen meningslös).
Varje ny säsong kör vi om samma examination som vi körde för Mayo: tränar på tidigare år, testar på det aktuella, väljer vinnare. Detta är inte en engångslansering av modell, det är kontinuerlig omkalibrering.
Avslutningsvis
Svampprognoser är inte magi och inte gissningar. Det är ett försök att se skogen bättre än kalender och intuition tillsammans, samtidigt som vi ärligt berättar för användaren var modellen är säker och var den inte är det.
Vi gör detta för att vi själva är svampplockare. Alla i teamet har förlorat minst en dag per säsong i en tom skog, och denna produkt började som ett sätt att sluta förlora dessa dagar. Om den smärtan är bekant för dig, prova prognosen för din region.
Lanseringsspecial 2026
50% rabatt på ditt första premiumår! Prenumerera för att få din exklusiva rabattkod.
Tillgänglig i Irland, Storbritannien, Sverige och Frankrike · Tyskland kommer snart
Namn
E-post*
Plattform*