
Comment nous avons choisi le modèle de ML qui alimente votre prévision. Coup d’œil dans les coulisses : 15+ modèles, 4 000 observations vérifiées de girolles dans le comté de Mayo et l’examen équitable de 2025.
En 2021, le pic des girolles en Irlande est tombé en septembre. En 2025, il a eu lieu en juillet. Deux mois d’écart, même espèce, même pays. Le calendrier ne correspond pas toujours, la météo change d’une année à l’autre, et le journal de l’an passé ne se répète pas toujours. Dans le comté de Mayo, notre équipe a collecté plus de 4 000 observations vérifiées de girolles sur six ans, et en 2025 nous avons soumis ces données à un examen équitable face à 15 modèles de ML différents. Cet article raconte comment nous les avons comparés, qui a gagné et pourquoi vous utilisez aujourd’hui précisément ce modèle dans ShroomCast.

Pourquoi prévoir les champignons
La forêt n’est pas un calendrier. Regardez les observations de girolles à travers l’Irlande sur les 7 dernières saisons sur un seul graphique :
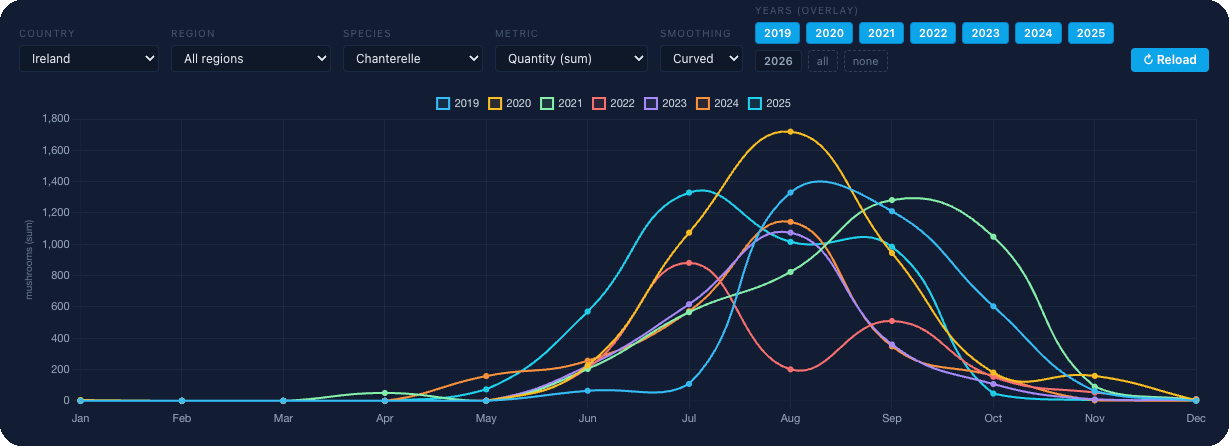
En 2021, vous seriez allé en forêt en juillet et n’auriez trouvé que de la mousse. En 2025, vous auriez attendu septembre et raté le pic de six semaines. Ce n’est pas une anomalie isolée, c’est la norme : température, précipitations, humidité du sol, type de forêt, cycles lunaires, chacun de ces facteurs déplace la fructification de jours et de semaines, et leur effet combiné peut faire glisser le pic de juillet à septembre et inversement.
Les cueilleurs travaillent ainsi « à l’instinct » depuis des siècles, sur des signes mal formalisés comme « après l’orage, dans quatre jours, direction la chênaie. » Dans certaines forêts et saisons, cela fonctionne. À l’échelle d’un pays et d’une année, c’est une loterie.
Avec des données, le problème devient soluble. Si vous avez des milliers de fructifications réellement enregistrées pour une région, liées à la météo de ces jours-là, vous pouvez trouver des motifs dans ces données et prévoir la prochaine poussée. C’est le problème que ShroomCast existe pour résoudre.
Données. Le fondement
À la sortie d’aujourd’hui :
- 750K+ observations vérifiées de champignons depuis 2019.
- 230+ régions couvertes par le modèle en Europe.
- 7+ années de données météo pour chacune de ces régions.
- 14 espèces modélisées individuellement (girolle, cèpe, morille, lactaire délicieux, bolet bai, armillaire couleur de miel et d’autres).
Nous collectons les sources de la même manière à chaque fois : bases d’observation publiques plus les relevés de terrain de notre équipe et des sources fiables avec lesquelles nous travaillons directement. Chaque enregistrement n’est pas juste « trouvé ce jour-là » mais un triplet (région, espèce, date) plus le contexte météo et sol complet autour de ce jour.
Ce que nous analysons
Chaque espèce dans chaque région est modélisée séparément. La girolle a ses déclencheurs, la morille les siens, le cèpe les siens. Dans un même modèle, nous examinons cinq groupes de caractéristiques :
- Météo : température de l’air, précipitations, humidité, pression atmosphérique, couverture nuageuse.
- Sol : température du sol, humidité du sol, composition.
- Forêt : type (résineux, feuillu, mixte), altitude, microclimat local.
- Cycles naturels : phases lunaires, motifs saisonniers, fenêtres de fructification propres aux espèces.
- Dynamique historique : ce qui s’est passé dans cette région avec cette espèce dans les années précédentes dans des conditions similaires.
Étude de cas : comté de Mayo, Irlande, girolle
Pour montrer comment nous choisissons un modèle, nous prenons une région et une espèce. Mayo est le banc d’essai idéal pour plusieurs raisons : un large pool d’observations sur de nombreuses années (plus de 4 000 pour la seule girolle), et nous avons complété le dataset avec les données girolle de toute l’Irlande pour le contexte.
De 2019 à 2024, c’était notre période d’entraînement. Les modèles ont « appris » sur ces six saisons : quelles combinaisons de météo et de sol ont précédé les fructifications réelles, lesquelles non. Nous avons laissé 2025 intact. C’est l’avenir qu’aucun modèle n’avait vu pendant l’entraînement.
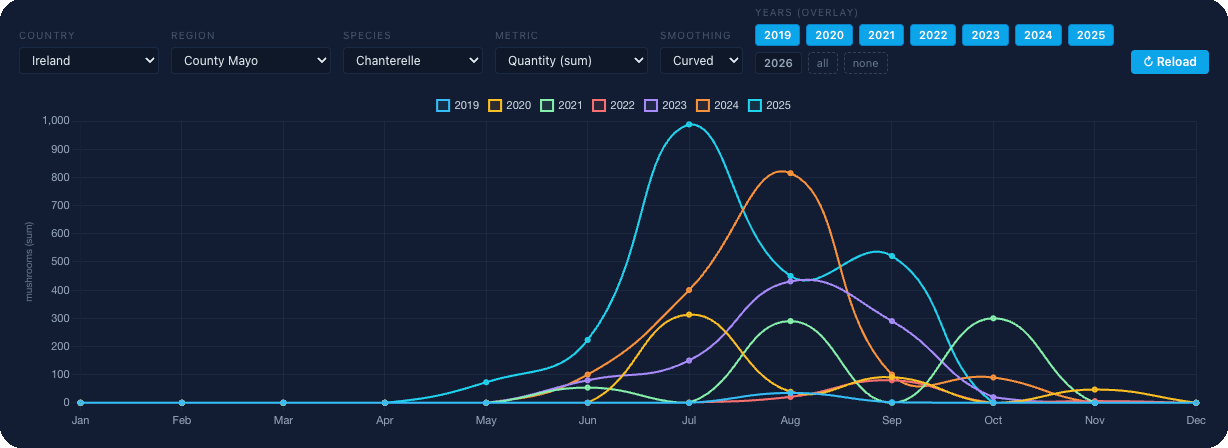
Chaque point du graphique ci-dessus est soit une trouvaille de notre équipe, soit une observation vérifiée provenant de sources fiables avec lesquelles nous travaillons. Aucune donnée inférée. Seulement ce qu’un humain a réellement vu et enregistré.
Comment nous avons choisi le modèle
C’est la partie que la plupart des utilisateurs ne voient jamais : l’appel d’offres de modèles.
Nous avons testé plus de 15 architectures ML différentes. Leurs noms spécifiques importent moins que l’approche elle-même : chaque modèle regardait les mêmes données et devait apprendre à prédire la probabilité de fructification de girolles à Mayo pour chaque semaine de 2025. Dans chaque architecture, nous avons essayé des dizaines de variations : différents horizons de caractéristiques, différentes régularisations, différentes manières d’encoder la saisonnalité.
La règle principale de sélection : un modèle était jugé non pas sur sa capacité à mémoriser les anciennes données (n’importe quelle machine surajustée le fait) mais sur la précision avec laquelle il prédisait 2025, l’année qu’il n’avait pas vue à l’entraînement. C’est l’examen équitable.
Modèle 1 contre Modèle 2
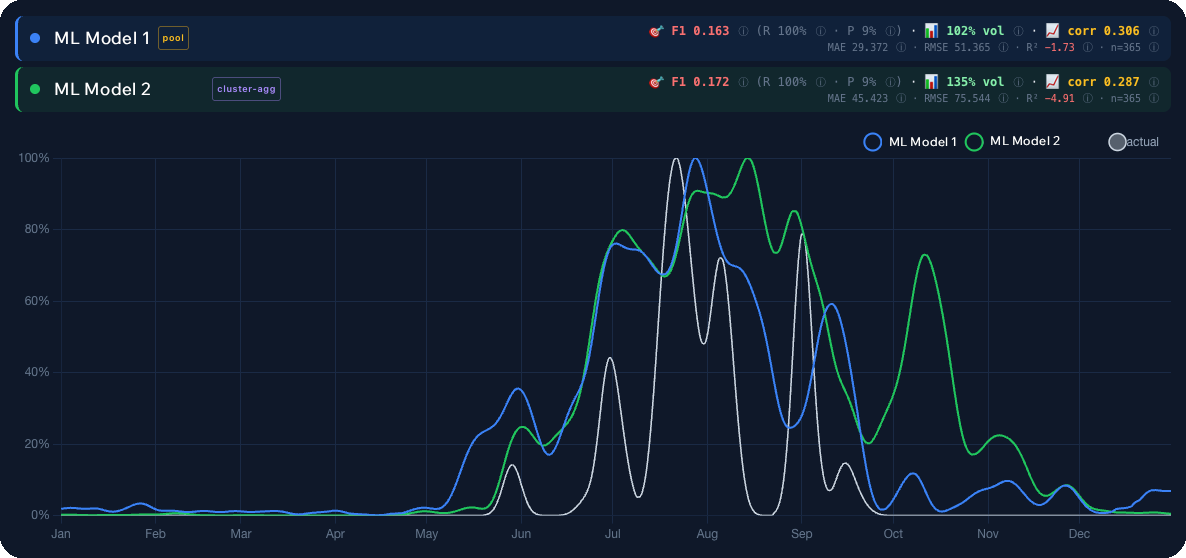
Le graphique ci-dessus montre le même ensemble d’observations réelles de 2025, avec les prévisions de deux modèles finalistes superposées. La ligne bleue (ML Modèle 1) suit proprement les vraies poussées : elle attrape le début de saison, ne manque pas le pic d’août et décroît correctement en octobre. L’autre variante soit accuse du retard, soit surestime l’intensité pendant les semaines « calmes ».
La différence semble petite à l’œil mais est énorme en pratique. Une prévision « Excellente » supplémentaire dans une semaine sans champignons vous coûte une journée gâchée et un plein d’essence. Un pic manqué vous coûte la saison. Le gagnant a donc été le modèle qui, en moyenne, a le moins induit l’utilisateur en erreur sur 2025.
Nous avons exécuté la même procédure pour chaque espèce et pour chacune des 230+ régions. La même architecture n’a pas gagné partout. Dans les régions à base d’observations plus mince, des modèles plus conservateurs l’ont emporté, dans les régions denses, les variantes plus sensibles ont pris la tête. Le pipeline de production final est assemblé à partir de ces choix localement optimaux.
Ce qui arrive vraiment dans l’application
Les modèles gagnants tournent en production et calculent désormais une prévision sur 14 jours pour chaque espèce dans votre région. Quatre fois par jour, le pipeline récupère la météo fraîche, met à jour les caractéristiques, exécute le modèle et publie le résultat. Vous le voyez sous la forme d’une échelle codée par couleur :
- 0-20% Très faible (violet, pas aujourd’hui)
- 20-40% Faible (bleu, presque aucune chance)
- 40-60% Modérée (vert, vaut la peine de vérifier vos spots habituels)
- 60-80% Élevée (jaune, les conditions sont bonnes)
- 80-100% Excellente (orange, prenez le panier)
Donc tout ce qui est sorti de milliers d’heures d’entraînement de modèle, ce sont cinq couleurs et un chiffre par jour. C’est ainsi que cela doit être. Modèle complexe, réponse simple.
Où cela fonctionne le mieux et où non
La transparence fait partie du produit. Toutes les régions n’ont pas une densité de données égale, et nous ne le cachons pas.
Le plus solide : Royaume-Uni et Irlande. Nous avons ici la densité d’observations la plus élevée et les séries par espèce les plus longues. Mayo ci-dessus est un exemple de ce à quoi ressemble une région bien saturée.
Bon : la moitié sud de la Suède (Götaland et la plus grande partie de Svealand). Nous avons étendu la couverture ici récemment et obtenons déjà un signal stable.
Plus faible : le nord de la Suède (Norrland), surtout le Norrbotten subarctique. Les fenêtres de fructification sont plus courtes, les observations moins nombreuses. Le modèle tourne encore mais la bande d’incertitude est plus large. Nous l’affichons honnêtement dans l’application : là où les données sont rares, la prévision est plus prudente.
Ce n’est pas un défaut, c’est la forme du problème. Plus de données, des réponses plus nettes. Chaque saison, nous ajoutons de nouvelles observations et recalibrons les modèles.
Pourquoi une région, pas un point
Un point technique qui revient régulièrement. ShroomCast n’affiche délibérément pas de prévisions à des points spécifiques sur la carte. Seulement par région (des dizaines de kilomètres carrés).
La raison n’est pas technique. Si l’application disait « dans cette clairière, à 50 mètres au nord de ce virage, il y a 92% de probabilité de girolle aujourd’hui », une semaine plus tard cette clairière n’existerait plus. Les forêts ne survivent pas aux raids guidés par coordonnées. Nous travaillons donc au niveau régional et laissons les spots personnels aux cueilleurs eux-mêmes.
ShroomCast ne stocke pas vos emplacements. Ne se souvient pas où vous avez marché. Ne construit pas votre carte personnelle. C’est intentionnel, pas un oubli.
Et ensuite
Pour l’instant, la couverture est le Royaume-Uni, l’Irlande et la Suède. La prochaine sortie est la France, puis l’Europe continentale plus largement. Nous ajoutons de nouvelles espèces à mesure que la base d’observations croît assez pour les soutenir (au moins quelques milliers d’observations validées par région, sinon le modèle est vide de sens).
Chaque nouvelle saison, nous refaisons le même examen que pour Mayo : entraîner sur les années passées, tester sur l’année en cours, choisir les gagnants. Ce n’est pas un lancement ponctuel, c’est une recalibration continue.
Pour conclure
La prévision des champignons n’est ni magie ni devinette. C’est une tentative de voir la forêt mieux que le calendrier et l’intuition réunis, tout en disant honnêtement à l’utilisateur où le modèle est confiant et où il ne l’est pas.
Nous faisons cela parce que nous sommes nous-mêmes des cueilleurs. Chaque membre de l’équipe a perdu au moins une journée par saison dans une forêt vide, et ce produit a commencé comme un moyen d’arrêter de perdre ces journées. Si cette douleur vous est familière, essayez la prévision pour votre région.
Offre de lancement 2026
50% de réduction sur votre première année Premium ! Abonnez-vous pour recevoir votre code promo exclusif.
Disponible en Irlande, au Royaume-Uni, en Suède et en France · Bientôt en Allemagne
Nom
E-mail*
Plateforme*